




















在国内厂商纷纷在产品中加入AI能力的当下,印象笔记悄然上线了“印象AI”。不同于大多数需要“内测”和“邀请码”的AI产品,用户只要更新印象笔记至最新版本即可直接使用AI功能进行文章写作。
4月19日,新京报贝壳财经记者获悉印象笔记已将基于大语言模型AI功能赋能至旗下全线产品。根据印象AI用户协议,印象AI采用基于印象笔记自研的轻量化大语言模型大象GPT和国内外大语言模型相结合的混合模型方案。
贝壳财经记者体验印象笔记的AI功能发现,用户可使用AI进行文档的总结、续写、翻译等。在交互设计方面,AI的不少功能指明了具体场景,如“写作文”、“采访问题”、“广告文案”等。值得注意的是,用户可以使用“AI帮我写”功能向AI提问。
印象笔记董事长、CEO唐毅在接受新京报贝壳财经记者专访时表示,印象笔记从2018年就开始研发神经网络,彼时推出的“生成摘要”功能就基于AI能力,此次大象GPT的模型有百亿级参数,将针对知识管理和办公协作场景进行持续优化,同时未来也可能针对用户需求接入不同的大语言模型。
“印象AI”能力实测:写总结、写文案、回答问题
4月19日,新京报贝壳财经记者体验了印象笔记的AI功能,发现可以通过新建“超级笔记”后点击左侧加号或输入“/”等方式唤起AI菜单,其交互界面显示“印象AI体验版”字样,排在前列的选项有“AI帮我写”、“继续写作”、“头脑风暴”、“翻译”,而位列末尾的“更多”选项里则包括总结、解释、语法修复、简化语言、列提纲、写作文、现代诗、新闻稿、广告文案等在内的多个子选项。
贝壳财经记者首先尝试了印象AI的文章写作能力,记者以2022年北京卷的作文题目“学习今说”为题让印象AI写一篇不少于800字的议论文,其迅速生成了下图文章。
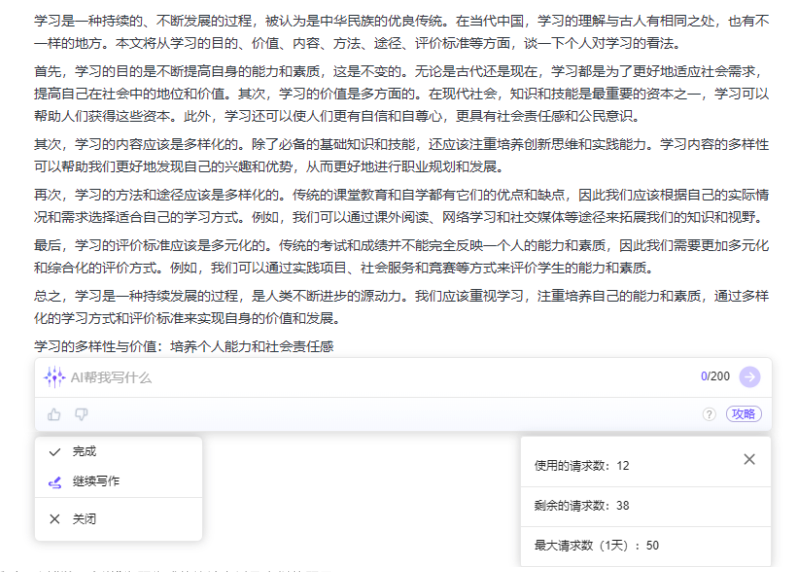
在印象AI生成内容后,还有“完成”以及“继续写作”两个选项,如果此时在输入框内再次提出要求,印象AI还能续接上文继续生成内容,如记者让其为上一段文章自拟一个标题,印象AI随即生成出了标题“学习的多样性与价值:培养个人能力和社会责任感”。
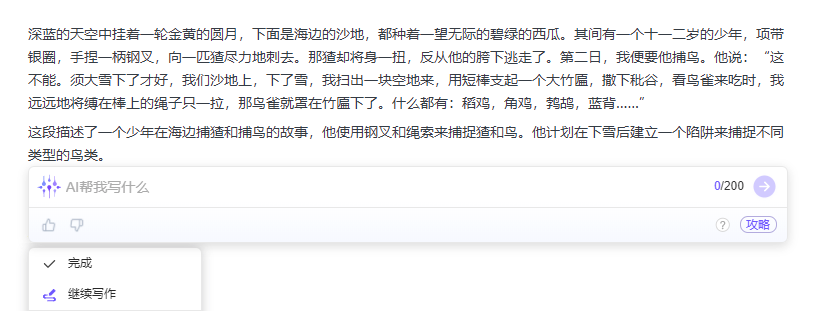
此后,记者又尝试了“总结”和“简化语言”能力,如将《少年闰土》中闰土刺猹和教鲁迅捕鸟的两段共计207字输入,得出的简写结果是:“这段描述了一个少年在海边捕猹和捕鸟的故事,他使用钢叉和绳索来捕捉猹和鸟。他计划在下雪后建立一个陷阱来捕捉不同类型的鸟类。”记者重复了10次简写操作,发现每次生成的简写结果都不一样,10次中有1次结果出现了事实错误(把猹说成了马),其余9次没有事实错误。
值得注意的是,贝壳财经记者测试印象笔记的“AI帮我写”能力时发现,其实际上已经隐含了类ChatGPT的问答能力,如记者在输入框中输入“如何实现中华民族伟大复兴”和“写一个中国足球冲出亚洲的方案”,印象AI均给出了回答。
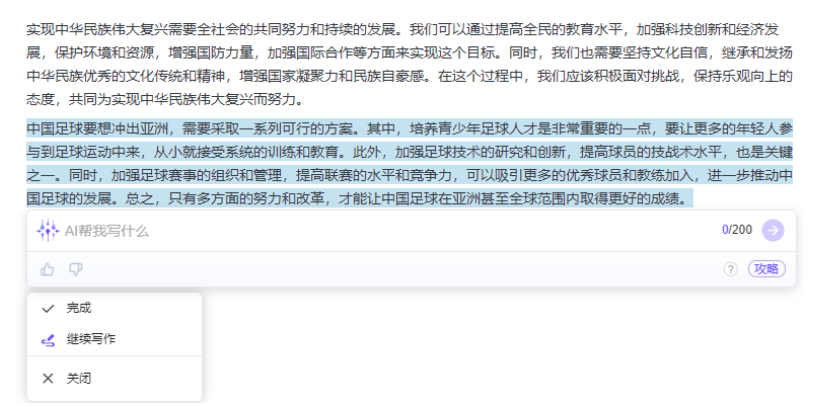
贝壳财经记者发现,其生成的答案在逻辑上并无明显差错,如表示中国足球冲出亚洲需要“培养青少年足球人才”。而当记者咨询其“鱼香肉丝是用什么鱼做的”等“陷阱类问题”时,其回答避开了陷阱,直言“鱼香肉丝是一道传统的川菜,但其名称与其实际的食材并无关联。据说这道菜的名称是由于其味道鲜美,给人以鱼的感觉而得名的”。不过,当记者咨询最近一届世界杯谁是冠军时,印象AI生成的内容是“法国”,显然其训练语料并未更新至最新时间,AI也未实时联网。
对于为何在印象AI的交互设计中,不直接给出问答式界面,而是设计了诸多已适配场景的子选项,唐毅对贝壳财经记者解释称,对话不一定是AI与用户最好的交流方式,在知识管理的场景下,让用户在已有模板内选择就好像是给了用户一个购物清单,而不是一张白纸似的心愿单,这将给一些“不知道怎么开始”的用户指明方向,在工作和书写的场景中更适用。此外,未来印象AI的交互菜单将进行个人定制化,“如媒体从业者可以把新闻稿和采访问题放到前面。”
做专注于知识管理场景百亿大模型 用户数据属于用户
贝壳财经记者试用印象AI发现,目前其AI功能已经可以实现部分新闻采写工作。
如在本篇文章的采访及撰写中,记者尝试让印象AI列出“采访印象笔记老板要问的问题”,其迅速列出了10个问题,包括“请问印象笔记对于人工智能技术的研究和应用有哪些计划和投入?”“印象AI的技术架构和算法是如何设计的?”“您认为人工智能在未来的发展中有哪些潜在的风险和挑战?”等。

对此,印象研究院负责人常诚在回答上述由自家AI生成的问题时表示,大象GPT为百亿级别的大语言模型,在结构上参考了“BLOOM”、“OPT”、“ LLaMA”等先进的类GPT3.5能力的开源大语言模型,并在模型结构上做了微调,同时在训练过程中引入了新的自行加工的指令数据集,这也是用户协议中表示“采用混合模型方案”的原因之一,“我们并不对标千亿级的大模型,而是更加专注垂直于知识管理场景。”
常诚告诉贝壳财经记者,在大语言模型的基础算法早已开源的今天,GPT4之所以能够做到当前的高度,并非在模型方面掌握了多少“独家秘籍”,而是在模型训练过程和训练数据整理加工等多方面的多年经验积累,这些经验中涉及的技巧是从大量失败的实验中堆积出来的,“对于印象笔记来说,我们也有信心在一个专注的领域内不断投入成本进行优化,我们有大量的忠实用户,他们在知识管理中有着非常深入的AI使用场景,这也使得我们拥有独特的优势。”
值得注意的是,贝壳财经记者在阅读印象AI用户协议时发现,其在“数据收集和训练”一栏中标明“请您理解并同意,您在使用印象AI期间输入的内容和指令,将会被用于印象笔记自有语言模型的数据收集和训练”。
对于该条款,印象笔记产品负责人刘璨对贝壳财经记者表示,用于训练模型的数据仅限于用户在AI输入框内输入的指令内容,即用户向AI提出的问题文本,而用户的其他私有数据不会被用于模型训练。
常诚表示,印象AI未来会针对用户反馈持续迭代,以在不同场景下能生产质量更高更多样性的回答,并考虑引入多模态数据。此外,印象AI未来一个可能的发展方向是,结合印象笔记“个人知识库”概念,用户可以选择用私人数据训练和部署自己的专有版本语言模型,服务于自己或者自己的朋友。
“作为研究人员,不论是在学术界还是工业界,我们不希望用户把大语言模型当做一个事实核查的知识库系统,因为它本质上是一个统计模型,我们更应该把大模型当做一个推理工具,如果你要写一个采访稿,大模型可以胜任单步推理,但对于特别专业的问题,用户应该至少能判断结果的质量,不能单纯指望语言模型完全替代用户本身。当然,我们也会持续调优印象AI模型,而且我们的用户是非常多样的,可能有用户在某些非常专业的领域需要高级的处理,对此未来我们不排斥在合规的前提下接入国内外的大模型以解决用户问题。”唐毅告诉贝壳财经记者。
在行业层面,贝壳财经记者注意到4月18日WPS、钉钉都官宣旗下产品将注入AI能力,对于行业内未来可能产生的竞争,唐毅表示印象笔记的AI战略启动早研究深,拥有自己的属性,目前用户可以在官网下载最新版本直接体验,“我们将持续探索人机交互的最优解,给用户提供最符合直觉的交互方式。”
报道来源:新京报





